JobSet
JobSet workloads on AIchor are managed by JobSet, a Kubernetes-native CRD maintained that lets you run a group of Jobs as a single distributed workload. It is the best fit when an experiment is made of several different job groups (for example a master plus a few worker pools, each with its own resources) instead of a single fixed master/worker layout.
How to use
Select JobSet by setting spec.operator: jobset in your manifest. Under spec.types declare one entry per job group; the name of each entry is up to you.
kind: "AIchorManifest"
apiVersion: "0.2.3"
spec:
operator: "jobset"
image: "image"
command: "python3 -u main.py"
types:
master:
count: 1
resources:
cpus: 1
ramRatio: 2
worker:
count: 5
resources:
cpus: 4
ramRatio: 3
accelerators:
gpu:
count: 1
type: "gpu"
product: "NVIDIA-A100-SXM4-80GB"
worker-2:
count: 1
resources:
cpus: 4
ramRatio: 3
For the full field-by-field specification, see the Manifest Reference. For more complete examples, see the Manifest Examples.
Available types
Under spec.types any name can be set for the job groups, as long as it matches ^[a-z0-9-]+$ — lowercase letters, digits and hyphens only, and the name cannot start with a digit or hyphen. At least one job group must be defined.
Three fields control the shape of each job group:
count— number of jobs in this group. In the example above,workerhascount: 5, meaning 5 independent Kubernetes Jobs are created for the worker group.completions— number of pods inside each job. Withworker.count: 5andworker.completions: 4, the worker group runs 5 × 4 = 20 pods in total. Forworker.resources.cpu: 4andworker.resources.ramRation: 3, this setup will use 5*4=20 cpus and 5*4*3=60GB of RAM.parallelisms— how many of those pods run at the same time inside each replica. Withworker-2.parallelisms: 1, pods run one after the other: when one finishes, the next starts, untilcompletionsis reached.
Injected environment variables
The JobSet CRD natively injects:
JOB_COMPLETION_INDEX
AIchor also adds the following variables to every pod:
The example values below assume the master + worker + worker-2 manifest above (count of 1, 5, and 1):
| Variable | Description | Example |
|---|---|---|
JOB_COMPLETION_INDEX | The pod position inside its job replica | 2 (pods worker-0-2 and worker-3-2) |
JOB_INDEX | The replica index of the job this pod belongs to | 1 (pods worker-1-2 and worker-1-3) |
GLOBAL_REPLICAS | Total number of job replicas across all types. | 7 (1 master + 5 worker + 1 worker-2) |
JOB_GLOBAL_INDEX | Index of this pod's job replica among all job replicas across all types, from 0 to GLOBAL_REPLICAS - 1. | 0–6 |
REPLICATED_JOB_NAME | The type name this pod belongs to. | master, worker, or worker-2 |
REPLICATED_JOB_REPLICAS | Total number of job replicas for this pod's type. | 1 (master), 5 (worker), 1 (worker-2) |
Examples
One group, one job
spec:
operator: "jobset"
command: "python3 main.py"
types:
worker:
count: 1
One Kubernetes Job is created with one pod. The pod is named worker-0-0.
time ───────────────────────────────►
worker 0 [──────────────────────────────] worker-0-0
One group, multiple jobs
spec:
operator: "jobset"
command: "python3 main.py"
types:
worker:
count: 4
Four Kubernetes Jobs are created, each with one pod. All four pods run concurrently.
| Pod | Job index | Pod index |
|---|---|---|
worker-0-0 | 0 | 0 |
worker-1-0 | 1 | 0 |
worker-2-0 | 2 | 0 |
worker-3-0 | 3 | 0 |
time ───────────────────────────────►
worker 0 [──────────────────────────────] worker-0-0
worker 1 [──────────────────────────────] worker-1-0
worker 2 [──────────────────────────────] worker-2-0
worker 3 [──────────────────────────────] worker-3-0
Two groups
spec:
operator: "jobset"
command: "python3 main.py"
types:
master:
count: 1
worker:
count: 4
Five pods run concurrently: one master (master-0-0) and four workers (worker-0-0 through worker-3-0).
time ───────────────────────────────►
master [──────────────────────────────] master-0-0
worker 0 [──────────────────────────────] worker-0-0
worker 1 [──────────────────────────────] worker-1-0
worker 2 [──────��────────────────────────] worker-2-0
worker 3 [──────────────────────────────] worker-3-0
Two groups, multiple pods per job (2 pods per job concurrent)
spec:
operator: "jobset"
command: "python3 main.py"
types:
master:
count: 1
worker:
count: 4
completions: 2
parallelisms: 2
Nine pods run concurrently. parallelisms: 2 is required here — without it, parallelisms defaults to 1 and each job would run its pods one at a time.
| Group | Jobs | Pods per job | Total pods |
|---|---|---|---|
master | 1 | 1 | 1 |
worker | 4 | 2 | 8 |
Worker pod names: worker-0-0, worker-0-1, worker-1-0, worker-1-1, worker-2-0, worker-2-1, worker-3-0, worker-3-1.
time ───────────────────────►
master [──────────────────────] master-0-0
worker 0 [──────────────────────] worker-0-0
[──────────────────────] worker-0-1
worker 1 [────────────��──────────] worker-1-0
[──────────────────────] worker-1-1
worker 2 [──────────────────────] worker-2-0
[──────────────────────] worker-2-1
worker 3 [──────────────────────] worker-3-0
[──────────────────────] worker-3-1
Two groups, sequential pods per job
spec:
operator: "jobset"
command: "python3 main.py"
types:
master:
count: 1
worker:
count: 4
completions: 4
parallelisms: 1
Each worker job runs its pods one at a time: worker-N-0 completes, then worker-N-1 starts, and so on. At any point during the experiment, 5 pods are active: the master and one pod per worker job. 16 worker pods execute in total across the lifetime of the experiment (4 jobs × 4 sequential pods each).
time ──────────────────────────────────────────────►
master [──────────────────────────────────────────]
worker 0 [──────] [──────] [──────] [─────��─]
worker 1 [──────] [──────] [──────] [──────]
worker 2 [──────] [──────] [──────] [──────]
worker 3 [──────] [──────] [──────] [──────]
pod 0 pod 1 pod 2 pod 3
Embarrassingly parallel (hyperparameter sweep)
No coordinator needed. Each job is fully independent and uses JOB_INDEX to select its hyperparameters.
spec:
operator: "jobset"
command: "python3 train.py"
types:
trial:
count: 16
resources:
cpus: 4
ramRatio: 2
accelerators:
gpu:
count: 1
type: "gpu"
product: "NVIDIA-A100-SXM4-80GB"
16 independent training jobs run concurrently. Each pod reads JOB_INDEX (0–15) to pick its hyperparameter configuration.
time ───────────────────────────────►
trial 0 [──────────────────────────────]
trial 1 [──────────────────────────────]
trial 2 [──────────────────────────────]
...
trial 15 [──────────────────────────────]
Heterogeneous pools
A coordinator manages a GPU worker pool and a CPU worker pool with different resources. JobSet treats them as a single experiment.
spec:
operator: "jobset"
command: "python3 main.py"
types:
coordinator:
count: 1
resources:
cpus: 4
ramRatio: 2
gpu-worker:
count: 4
resources:
cpus: 8
ramRatio: 4
accelerators:
gpu:
count: 1
type: "gpu"
product: "NVIDIA-A100-SXM4-80GB"
cpu-worker:
count: 8
resources:
cpus: 16
ramRatio: 4
13 pods run concurrently. JOB_GLOBAL_INDEX and REPLICATED_JOB_NAME let each pod know its role and position.
time ───────────────────────────►
coordinator 0 [──────────────────────────]
gpu-worker 0 [──────────────────────────]
gpu-worker 1 [──────────────────────────]
gpu-worker 2 [──────────────────────────]
gpu-worker 3 [──────────────────────────]
cpu-worker 0 [──────────────────────────]
cpu-worker 1 [──────────────────────────]
...
cpu-worker 7 [──────────────────────────]
Sequential batch processing
A single job processes 100 batches with up to 4 running at a time. No distributed coordination — pure throughput.
spec:
operator: "jobset"
command: "python3 process.py"
types:
processor:
count: 1
completions: 100
parallelisms: 4
resources:
cpus: 4
ramRatio: 2
One Kubernetes Job runs 100 pods in waves of 4. Each pod reads JOB_COMPLETION_INDEX (0–99) to know which batch to process.
time ────────────────────────────────────────────────────────────────────────►
processor [p-0][p-1][p-2][p-3] [p-4][p-5][p-6][p-7] ... [p-96][p-97][p-98][p-99]
Mixed concurrency
One group runs fully parallel pods (fast pre-processing), another runs sequential pods (slower evaluation). Both groups run concurrently with each other.
spec:
operator: "jobset"
command: "python3 main.py"
types:
preprocessor:
count: 4
completions: 4
parallelisms: 4
resources:
cpus: 4
ramRatio: 2
evaluator:
count: 4
completions: 4
parallelisms: 1
resources:
cpus: 8
ramRatio: 4
accelerators:
gpu:
count: 1
type: "gpu"
product: "NVIDIA-A100-SXM4-80GB"
Preprocessor jobs run all 4 pods at once. Evaluator jobs run one pod at a time, reusing the same GPU slot for each sequential evaluation.
time ─────────────────────────────────────►
preprocessor 0 [────][────][────][────]
preprocessor 1 [────][────][────][────]
preprocessor 2 [────][────][────][────]
preprocessor 3 [────][────][────][────]
evaluator 0 [──────] [──────] [──────] [──────]
evaluator 1 [──────] [──────] [──────] [──────]
evaluator 2 [──────] [──────] [──────] [──────]
evaluator 3 [──────] [──────] [──────] [──────]
pod 0 pod 1 pod 2 pod 3
Scheduling behaviour
Kubernetes schedules pods independently. If only one GPU is available when the experiment is submitted, one pod starts immediately; when it finishes, the next pending pod is scheduled, and so on. For embarrassingly parallel or sequential workloads this is the expected behaviour.
For synchronous workloads, this causes a problem: pods that start before their peers attempt to connect to the others and find them unavailable, consuming resources while idle or retrying.
JobSet has no native mechanism to wait for all pods to be ready before starting. See the Kubernetes Scheduling page for how to handle this, including Python examples for both a decentralized pattern (every pod waits for all others) and a coordinator pattern (workers wait for the coordinator, coordinator waits for all workers).
The 2D job/pod model
JobSet pods can be seen as a 2D array. A pod's name has the shape:
xxxxx-name-a-b-xxxxxx
Where:
nameis the type name you chose (e.g.master,worker,worker-2).ais the job index, from0tocount - 1.bis the pod index inside that job, from0tocompletions - 1.
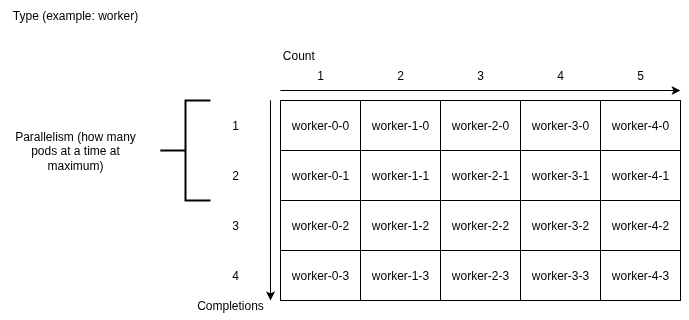
The diagram above visualises this layout: each row corresponds to one job (a axis), each column to one pod position inside the replica (b axis).